Article AWS: Scale On-Premise Backup & Archive Storage

By Insight UK / 17 May 2019 / Topics: Cloud
As businesses continue to generate and store large amounts of data, there is a growing demand for innovative data storage solutions that will not only reduce physical data centre infrastructure but also enable digital innovation. One of the ways to achieve this is to move long-term backup and archive storage to the AWS cloud to take advantage of the elasticity, low cost storage and on-demand use of data.
AWS provides a whole range of storage services for data movement, data storage, data security and management. The Amazon Simple Storage Service (S3) offers an infinite object storage service with industry-leading scalability, data availability, security, performance and 11 9’s durability. To leverage this technology and scale on-premise storage, AWS Storage Gateway can be deployed within an on-premise environment to create a hybrid storage solution with S3 as the storage target. This will enable the use of Amazon S3 as the backup and archive target for existing applications with little or no change.
What is AWS Storage Gateway?
The AWS Storage Gateway connects an on-premise software or hardware appliance with Amazon S3 to provide a seamless integration of an on-premise environment with AWS cloud for backup and archive of data. Some of the key features of the services include:
- Support for standard storage protocols, such as NFS, SMB and iSCSI
- Secure and optimised data transfer with bandwidth management and automated network resilience
- Local cache for low-latency on premises access to hot data
As indicated in Figure 1 below, AWS Storage Gateway offers file-based (file gateway), volume-based (volume gateway), and tape-based (tape gateway) storage solutions which can be deployed on existing on-premise infrastructure through:
- Virtual machine (VM) on VMware ESXi (on-premise or VMware Cloud on AWS)
- Virtual machine (VM) on Microsoft Hyper-V 2008 R2 and 2012
- Hardware Appliance (AWS Storage Gateway pre-loaded on a Dell EMC PowerEdge server)
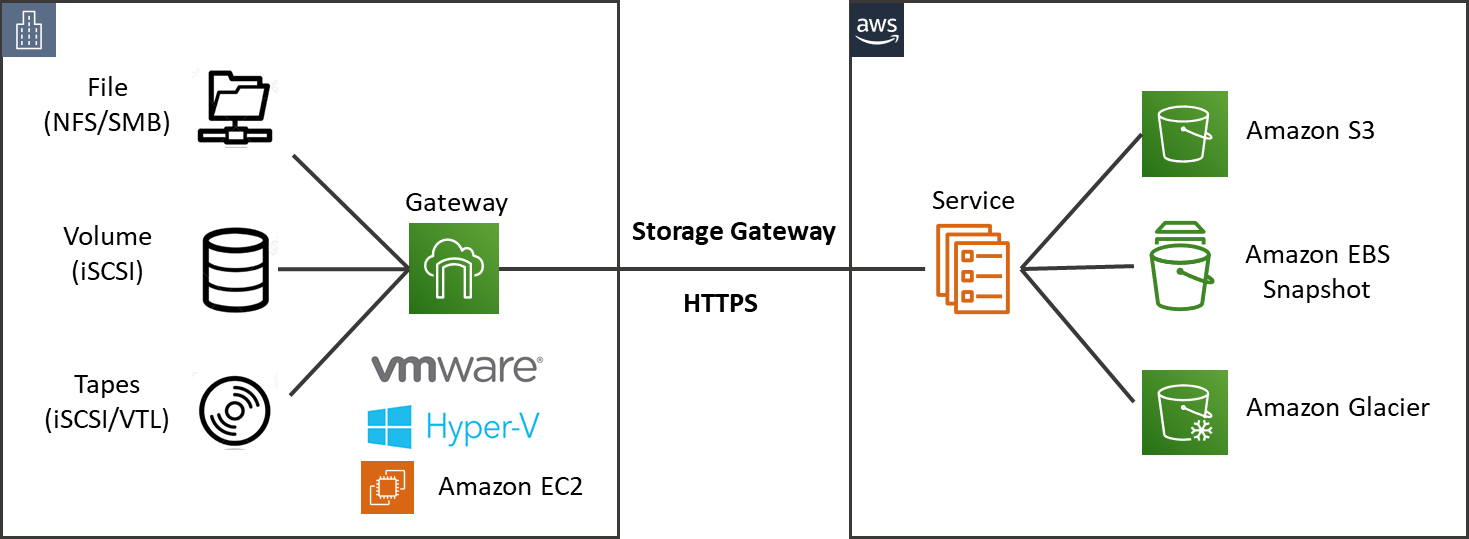
Figure 1: AWS Storage Gateway
This article will cover the architecture and use cases for the file gateway.
File Gateway
This is a virtual software appliance deployed in an on-premise environment as a virtual machine (VM), enabling storage of and access to files in S3 with low latency local caching. The service supports industry-standard file protocols such as Network File System (NFS version 3 and 4.1) and Server Message Block (SMB version 2 and 3). Data stored in S3 can be managed using lifecycle policies (for archiving), cross-region replication, and versioning. Figure 2 below shows the architecture of a file gateway and how data is transported from the file share clients to Amazon S3.
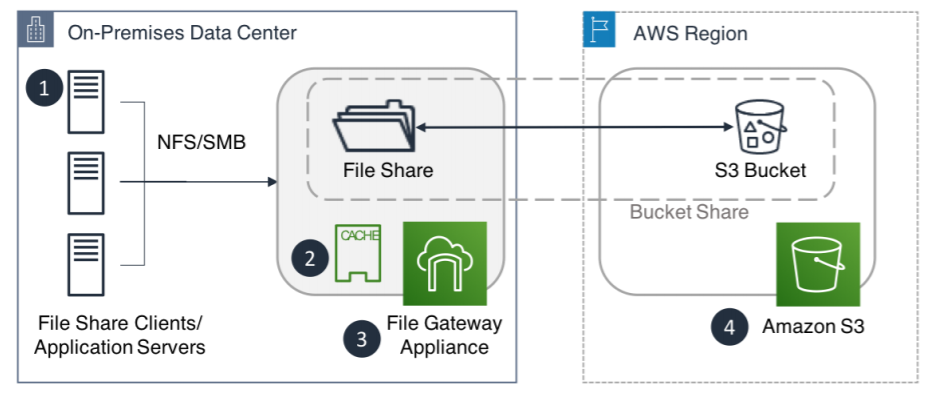
Figure 2: File Gateway
- Clients access objects as files using an NFS or SMB file share exported through an AWS Storage Gateway in the file gateway configuration
- Expandable read/write cache for the file gateway
- File gateway virtual appliance
- Amazon S3 provides persistent object storage for all files that are written using the file gateway
Each file share is paired with a single S3 bucket, and the contents of the bucket is available as files and folders to the file share client’s or application servers. Data written to the file share on the file gateway creates an identical object in S3 with the same file name. The newly created file is initially stored in Amazon S3 Standard and can be transitioned to Amazon S3 Standard - Infrequent Access or S3 One Zone - Infrequent Access storage classes for lower storage cost. Access to the file share can be controlled using the following built in capabilities of the file storage gateway:
- Default UNIX permission:
The permissions for read, write and execute for users, groups and others can be defined as part of the configuration for the mount point. This will be applied to the existing content of the S3 bucket ensuring that clients that access the mount point adhere to the permission set at the file or directory level.
- Using IP address:
For NFS file shares, an entire mount point and the associated Amazon S3 bucket can be protected by limiting mount access to individual IP addresses or a classless inter-domain routing block (CIDR range).
- Using Microsoft Active Directory:
For SMB file shares, Active Directory domains can be used to control access to the mount point and associated Amazon S3 bucket. Furthermore, access can be permitted to only a subset of users and hosts within the Active Directory domain to map the file shares as a drive on Microsoft Windows operating system.
Use Cases:
- Cloud Tiering:
Businesses with an on-premise environment running out of storage capacity can leverage AWS to scale on-premise storage without the need to acquire additional physical infrastructure. Using file gateway, cold data can be moved to Amazon S3 to take advantage of the durability, consumption-based pricing and scalability, while ensuring low-latency access to frequently used data. File gateway supports NFS and SMB protocols hence will not require any change to existing applications or interfaces. To implement cloud tier, simply deploy the file gateway appliance on a VM (running on ESXi or Hyper-V) and move data to it from existing SAN or NAS storage systems running out of capacity.
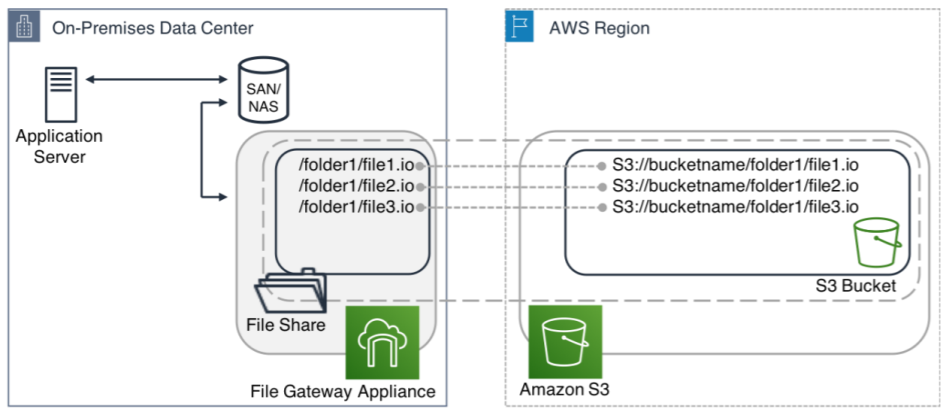
Figure 3: Using File Gateway for Cloud Tiering
- Hybrid Cloud Backup:
File gateway can be used as the backup target for application servers and file share clients using backup solutions that support NFS and SMB protocols. The local cache provides a low-latency interface for frequently used data while the cold data can be moved to AWS leveraging a mixture of Amazon S3 storage classes.
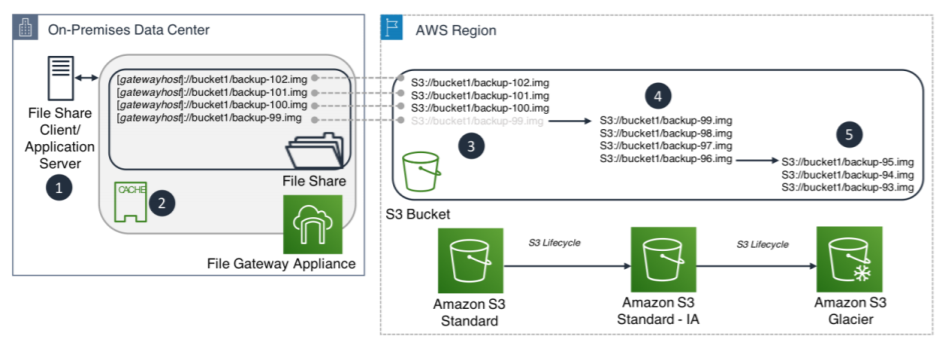
Figure 4: Using File Gateway to backup on-premise files
As indicated in Figure 4 above, Amazon S3 standard can be used as the initial location for backups for the first 30 days. At the end of 30 days the likelihood of restoration becomes infrequent and data can be transitioned into Amazon S3 standard infrequent access for lower storage cost. After a total of 60 days from the moving of the file to Amazon S3 standard, the likelihood of restoration becomes extremely rare and data can be archived in Amazon S3 Glacier. The transitioning of data to the various storage classes can be automated by setting up Amazon S3 lifecycle policies.
Note: File gateway can read files stored on any of these three storage classes: S3 Standard, S3 Standard - Infrequent Access and S3 One-Zone - Infrequent Access. Objects transitioned to Amazon S3 Glacier are visible on a list operations for the NFS files stored in the gateway, however, the files are not readable unless restored to one of the three storage classes supported by file gateway. It is recommended to only transition objects that do not require immediate access to Amazon S3 Glacier.
In summary, file gateway provides a solution that will enable businesses to scale out backup and archive storage without procuring additional physical infrastructure. Typically, using the cloud for storage is the first step in public cloud adoption for many businesses. Once the data is in the cloud, it will provide the enabler for other use cases such as application migration, disaster recovery and use of the data for analytics, artificial intelligence and machine learning.
If you are interested in finding out more, please contact your Insight Account Manager or get in touch via our contact form here.



